
Ch 3 - Unsupervised Learning: Combining Security and Data Science
Security Analytics

Authors: Securonix Labs
Machine learning is a subfield of artificial intelligence within computer science which is concerned with the design and analysis of algorithms that allow a computer system to learn from data without being explicitly programmed. In other words, the objective of machine learning is to develop learning algorithms that perform learning automatically to avoid the necessity for a human being to enlist all the information in a system. There are two major categories of machine learning algorithms classified based on how they learn from data: Supervised Learning makes predictions from data using observed labels, or outcomes, of events; and Unsupervised Learning discovers patterns and structure within data without the use of labels.
Labels are provided by human expertise, they are expensive to obtain due to the time and effort needed, and as a result are very scarce. Unlabelled data, however, is inexpensive, generally easy to obtain, and available in large quantities. This lends itself to the application of unsupervised learning methods to finding patterns in data that are indicative of threats and developing useful summaries that enable better detection.
In particular, unsupervised learning methods excel in detecting anomalous events and observations that might be indicative of malicious activity by a user, system or an application. This is especially useful in detecting novel attacks as well as emerging threats where there often isn’t a known pattern to leverage for detection. Furthermore, summaries obtained from patterns in data are used to obtain features that can later be leveraged for prediction in our supervised learning methods.
As opposed to supervised learning, where the goal is the prediction of a response variable, unsupervised learning does not have a straightforward goal and is much more subjective. Patterns obtained from unsupervised learning methods do not always result in a valuable outcome and, if simply applied, can lead to a large number of false positives. In order to utilize unsupervised learning methods successfully with high precision, we need security domain expertise to make sense of the patterns discovered and determine which areas to investigate.
When looking at unlabelled data, we can often pick up numerous patterns that are statistically interesting by using a wide range of unsupervised learning methods. However, these patterns may not be meaningful in the security sense as they lack context. In the example below, there are two clear spikes in the proxy traffic:
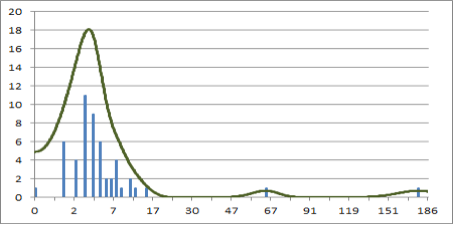
Histogram of the proxy traffic volume (left) clearly shows two outliers, highlighted in red (right).
Does it indicate a malicious activity, like data exfiltration, and warrants a security alert, or is it marketing uploading new videos and the alert will be just another false positive? We cannot determine it without knowing the security context of the event that includes event metadata, such as sender and payload attributes, and mapping to the appropriate threat indicators. Security expertise is required to create meaningful threat indicators and assemble them into effective threat models that amplify the risk and minimize false positives.
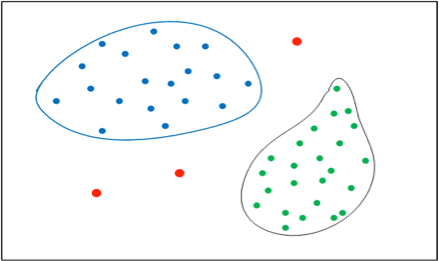
Users clustered by common access privileges form two groups, blue and green, with access outliers shown in red.
Unsupervised learning is also used to find patterns in data, categorize them, and investigate any exceptions. In the example above, users can be clustered by common access privileges to detect outliers. As with volume spikes, these findings are meaningless without additional information. Business domain knowledge is needed to interpret the clusters discovered and to determine the security implications of outlier entitlements in terms of access risk they represent. Without business domain and security expertise, unchecked anomaly detection is no better than a random alert generator.
Anomaly detection entails building profiles of normal activity, detecting anomalous deviations from these profiles, and quantifying the risk associated with these anomalies. However, many statistical approaches to anomaly detection assume that the observables are normally distributed, while real-world data exhibit far greater complexity. In the example below, using standard deviation from the mean to detect outliers fails since neither distribution is normal:
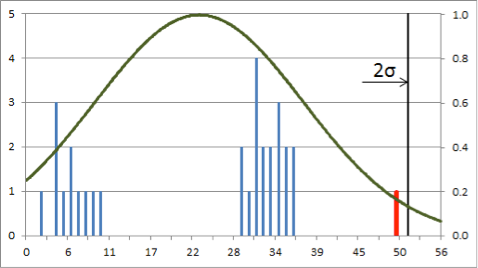
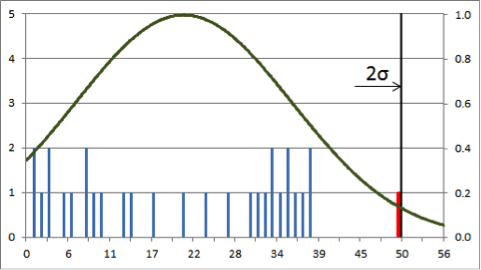
Assuming normal distribution to determine anomalies when the actual distribution is multimodal (left) or uniform (right) misses the outlier (red) in both cases.
Applying robust statistics instead, like median and Median Absolute Deviation (MAD), doesn’t help either: the outlier in uniform distribution is still missed by a wide margin, and while the one in the multimodal distribution is detected now, it’s at the cost of completely dismissing the leftmost cluster and treating all observations there as outliers.
To automate anomaly detection, we need an algorithm that can deal with any data distribution and that requires minimal operator intervention to onboard new data sources. Securonix patented approach to anomaly detection does just that. It creates a continuous profile by approximating each point in the data associated with the behavioral indicator of interest using Gaussian kernel density estimation (KDE) with variable bandwidth. This approach ensures that the profile works well for each and every data distribution by not relying on any assumptions about the underlying data generation process.
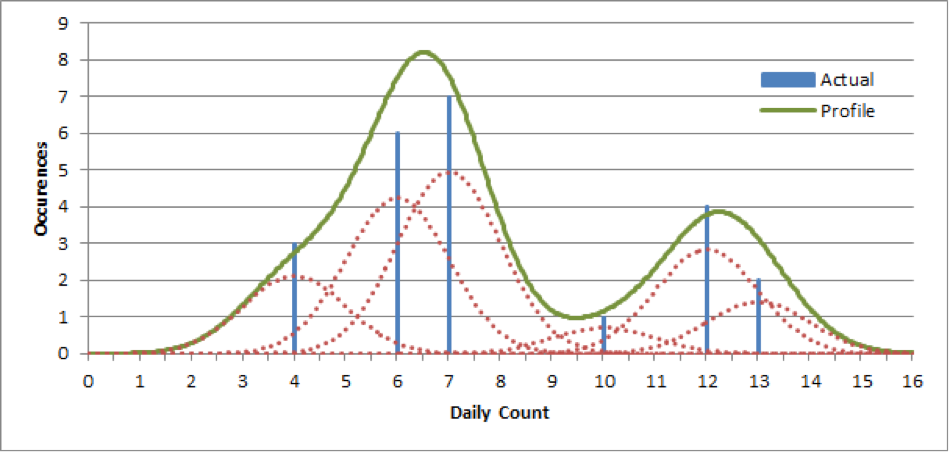
The dotted curves (red) are the normal kernel distributions for each count (blue). The line in green represents the behavioral profile, which is a sum of all the individual kernels for each of the measurements.
The anomaly is detected by examining the deviations from the normal behavioral profile. The anomaly probability is approximated by the Lorentz transformation of the profile, which gives the highest probability to the regions where there were no observations and the lowest to the regions with the highest number of observations:
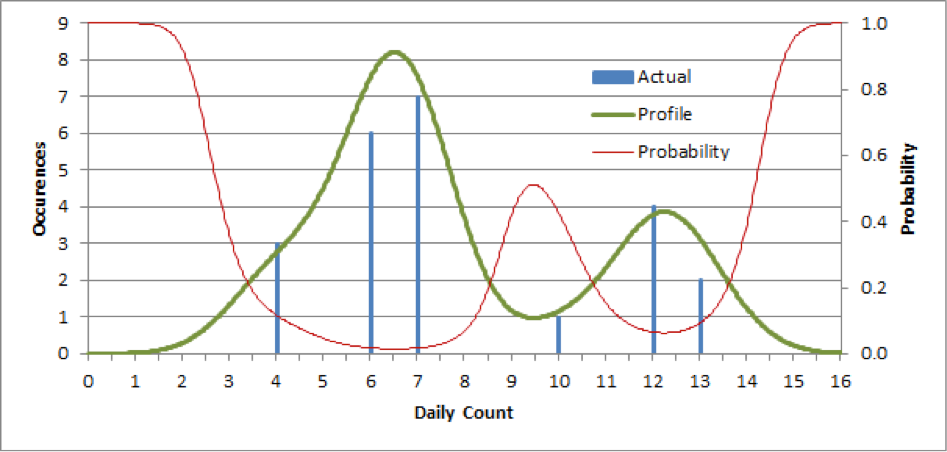
Anomaly probability function (red) is approximated by the Lorentz transformation of the behavioral profile, ranging from 0 where the number of observations is high to 1 where it’s low.
As the observations are streaming in, the anomaly probability function determines the outliers, which deviate significantly from the normal behavioral profile and are likely to indicate a malicious activity. The observations that fit the profile are considered normal and used to update the behavioral profile in real time to reflect changes in the environment.
An effective behavioral profile has to adapt to a changing behavior by seamlessly incorporating new traits and gradually forgetting old behavior. Adaptivity is achieved through profile aging, where older observations are taken with continuously decreasing weight and are eventually phased out beyond the aging period, allowing the profile to mutate over time. Profile aging has significant storage advantages over profile truncation since older observations are discarded as soon as they are incorporated into the profile. It also has a higher noise tolerance, emphasizing the actual trends and downplaying minute aberrations in the behavior:

Profile aging shows a changing behavior over time: peak at 67 shifts to 72, new peak emerges at 100, while the old one near 0 slowly degrades.
Adaptive behavioral profiles are at the core of Securonix behavioral analytics. Security expertise is utilized to select proper behavioral indicators and time series for each threat use case, with preference given to the ones that better reflect the pattern of life. For example, hourly logins and badging activity can identify after-hours access, while daily transaction count and proxy traffic volume can detect malicious data upload on the weekend. Automated KDE algorithm assures accurate anomaly detection in each of these cases, and profile aging and real-time updates reduce false positives in a dynamic environment. Detected anomalies are combined in the threat models for risk-scoring and amplification, resulting in prioritized and context-rich cases that are presented to the analyst for investigation.
Introduction – Data Science: A Comprehensive Look
Ch 1 – SIEM 2.0: Why do you need security analytics?
Ch 2 – Data Science: Statistics vs. Machine Learning
Ch 3 – Unsupervised Learning: Combining Security and Data Science
Ch 4 – Supervised Learning: Capturing The Thought Process Of An Analyst



