By Joshua Neil, Chief Data Scientist, Securonix
Executive Summary:
In this series of articles, I will be introducing basic and advanced concepts of security data science, written with the security executive in mind. In the security industry especially, it can be hard for executives to gain down-to-earth insight into this complex topic. It is my hope that this series will provide transparency, dispel myths, and equip executives with the necessary background to make good buying decisions and to take full advantage of machine learning in security operations.
The history of security data science — my lived experience
Data science is a relatively new field. While the term can be traced to John Tukey’s 1962 paper, “The future of data analysis”, the birth of an actual profession only began in the early 2000s. In security, adoption began in earnest in the 2010s, with the introduction of data scientists into security product R&D teams. More recently, we began seeing large enterprise security teams incorporate data scientists in operational/research settings, designing custom tools for SecOps.
As one of the early researchers in data-driven methods for security, I have seen almost the entire history of my profession. Starting my career as a security data scientist in 2000, my title was “statistician”, up until 2014. Before that, I spent almost 15 years at Los Alamos National Laboratory (LANL), working with incident response teams and the intelligence community. LANL is a US Dept of Energy security laboratory, responsible for conducting future-leaning research in all things national security. As a result of visionary leadership, I was asked to insert myself into a cyber research team. They said “Hey, he’s a statistician, they’re good with data. In security we have lots of data, let’s see what he comes up with.” To that end, I sat in the room with incident response, forensics, and later, as threat hunting emerged, to see how I could help.
Back then, I asked a lot of strange questions, like why don’t you add up all the numbers and divide by how many there are (take the average)? The IR folks were often confused as to why I wanted to do such strange things, but ultimately, my motives were to:
- Automate what I could or
- Accelerate human processes that I couldn’t
Let me give you an example from my experience to make things more concrete. At LANL, we found that lateral movement is one of the hardest behaviors to detect. Yet, lateral movement was present in nearly every serious incident we observed. It was something we called an “attack invariant”. It didn’t matter what the adversary wanted to do, they inevitably moved laterally. It was also very behavioral…there are no smoking guns with lateral movement. It can be done using living-off-the-land techniques that look very much like normal enterprise behavior. Lateral movement had the right components for me to tackle: important, hard to detect, and behavioral.
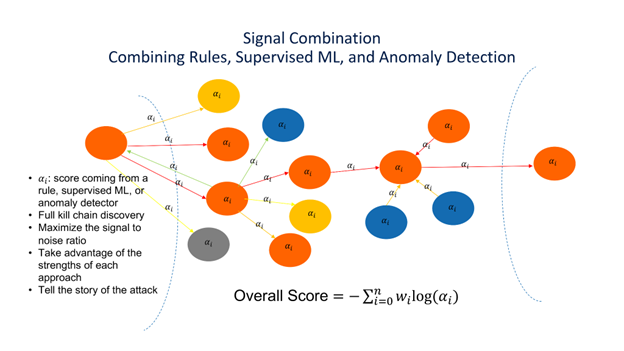
A conceptual diagram developed during my work on PathScan. Nodes are assets, edges are the flow of an attack through the enterprise. We see Initial penetration via phishing (left most node), followed by reconnaissance, lateral movement, data staging, and exfiltration. All individual elements are scored (the alphas), and an overall score for the attack is computed.
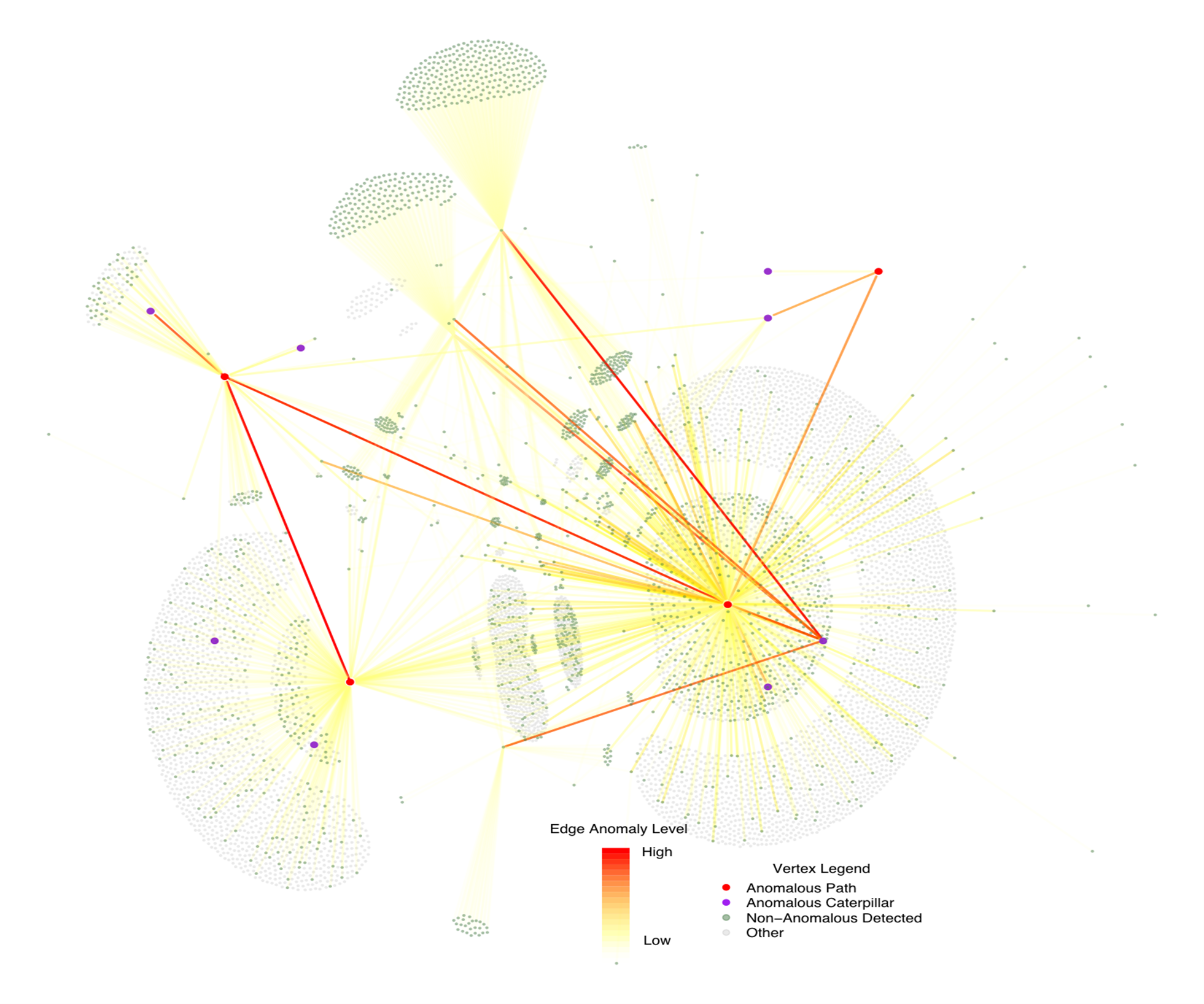
A real attack involving lateral movement within a large enterprise network, detected by PathScan. Color is proportional to anomaly level, and one can see the multihop behavior as the attack proceeded along the red path.
My approach? Watch the human analysts, and ask “how do they determine lateral movement?” The answer is complicated and very context-dependent, but several points emerged:
- Lateral movement is behavioral, but it is visible through network and authentication data, as well as processes running on the end points.
- Lateral movement is a compound behavior. It requires multiple signals to be brought together to achieve low false positive, high-quality detections.
- “Weird connections” were a key feature. The analyst, having identified a compromised machine, would look for unusual inbound and outbound connections from that machine in order to find lateral movement.
To incorporate these elements of human analyst behavior, my team at LANL developed PathScan, a network anomaly detection tool designed to find lateral movement. It used statistical modeling to characterize normal behavior between machines, and then identified paths of anomalous multihop communication. PathScan proved to be effective in detecting lateral movement, and was adopted by US government entities and eventually licensed by Ernst & Young for use as part of their managed security services. The key lessons I took away were:
- Learn from the humans, they’re smart! Use their processes as a guide when building new ML-based use cases.
- Attacks that are characterized by behavior rather than signatures/rule-based detections are good fodder for machine learning. If you can’t write a rule to reliably detect something, call my team. If the adversary behavior looks a lot like normal user behavior, call us.
- We can usually generalize from rules, so engage us when you already have some specific behaviors in mind, and want to get more “fuzzy” to find more attacks.
- Anomaly detection is a good tool in our toolbox, because human analysts are interested in rare behavior, and we’re good at quantifying rarity. Be careful, though! Anomaly detection will produce many false positives unless you wrap it in a security context. Rare behavior alone is not sufficient to produce low false positive detection. Another way to put this is: All attacks are rare, but most rare behavior is NOT an attack!
6 lessons I learned from security teams
After observing operational teams over the intervening years, here are some key lessons I’ve learned:
- Context is an integral part of the SecOps process. If they have an alert in front of them, they want to know if it’s a true positive. How do they answer that? They look for supporting context. If they don’t find it, or if they find counterfactual evidence, they move on. Once they have validated a true positive, they continue to bring more context together to flesh out the attack footprint. That is, the entire process is about bringing context together! Therefore, a key goal for automation is to do this for them. This is perhaps the largest lesson I have learned: don’t design methods that work in isolation on one part of the kill chain. As a data scientist, endeavor to bring as much supporting evidence together as possible.
- When they get stuck, they ask “what was strange about this?”. Ok, great. I know how to identify strangeness, that’s called anomaly detection in statistics.
- Time dynamics are important. What happened first? How quickly did things transpire, and in what order? What are they going to do next? Time dynamics and sequences of events are areas upon which human analysts focus. Unfortunately, many data scientists are not trained to handle time, and many supervised machine learning methods aren’t designed to handle sequences. Statistical modeling, however, has a rich history of time-based modeling to rely upon.
- They hate false positives! False positives are the driver of cost in your SOC, and hide the actionable true positives in noise. While it is clear that investigating some level of noise is necessary to find the true positives, the false positive rate needs to be as low as possible while still retaining the capability to detect the true positives. How do analysts identify false positives? Context! See bullet 1.
- Interpretability is critical. Black box machine learning isn’t well accepted by the SecOps analyst, who is by nature suspicious, and needs good reasons to escalate. If they don’t understand WHY you think something is interesting, they’ll move on. Again, see bullet 1.
- We have very little labeled data in post-breach attack detection and response. By labeled data, I mean a large corpus of representative malicious and benign samples that are marked in the data as such, and this labeled data needs to represent typical future behavior so that the machine learning can make accurate predictions going forward. By post-breach, I mean that the AV and firewall protections have failed, and the attacker has access to internal assets of the enterprise. Supervised ML IS appropriate and used to good effect in antivirus settings, which is mostly out of scope for this blog series. The lack of post-breach labeled data is caused by several aspects:
- Attackers don’t tell us what they’re doing
- Attackers change their methods commonly
- Attackers have a huge set of options once they’ve gained access to the enterprise, meaning that any labels we do get might not represent future attack behaviors well
- The normal behavior of the enterprise changes constantly, so that the benign labeled data may not be representative either
As a result, while supervised ML, including deep learning, can and should be used when labels are available, it is not as applicable as it is in many other industries.
Guidelines for successfully utilizing data scientists in your security organization
I’ve learned a few hard lessons working in industry security research about how to gain the most out of a security data science team:
- Build a team. A lone data scientist is going to have a very hard time being effective.
- The team leader needs to have experience in security as well as data science. This is hard to find, but security knowledge is critical for leading such teams, since most if not all of the individual contributors won’t have security knowledge out of the box.
- Ensure the leader is targeting the most critical threats and needs of the business.
- Aggregate ALL security data into one repository. I get questions like “what data do you need?”. The fact is, we don’t know what data we’ll need until we get started. It’s our job to tell you what data is needed for any one use case, and to answer that, we need ALL the data.
- Enable the team with the right tooling. Typically, Python, R, open source libraries, and some form of big data processing such as Spark are required.
- Full stack data scientists are a myth. Instead, build a full stack team. Data science needs engineering, math/modeling, and security domain expertise.
- Ensure the data science team is closely integrated with security operations. One major mistake is to isolate the data science team in an ivory tower. If you want real impact from these teams, emphasize close working relationships with analysts, hunters, TI, etc. The mission: get data science algorithms facing operators with feedback as a constant process.
- Seek to enable self-service deployment for the data science team. The research environment may be a long way from the production infrastructure, and automation plus processes can help smooth the way for data scientists to make impact and produce actionable results in near real time for SecOps.
- Expect more failure than success. This is research, it takes time, and it takes experimentation and iteration to get to good methods. Be patient, encourage failure as a means to get to success. However, be wary of the sunk cost fallacy. Emphasize “failing fast” so that deadends can be quickly determined and the team can pivot to more effective avenues.
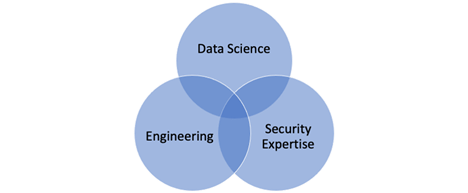
Security data science teams need a variety of skills, and you can’t hire them in one person. Hire for full stack teams, not full stack people.
Conclusions
Over the last 20 years, I have seen tremendous uplift in the ability to bring data science to good effect in security settings. The foundations needed to support our approaches have matured to a point where we are finally positioned to be effective. We have increased our sensing and data capture capabilities exponentially. You can’t do data science without good data, and since the best methods are those which seek tons of context, you can’t do data science without holistic data. We have cloud infrastructure and big data computing in a mature set of tools. The cloud is a game changer for data science in so many ways. There is a whole profession around security data science, with many thousands of researchers in the industry. It is an amazing experience to have gone from the early days, where I was a very strange member of a security team, to leading large product data science teams bringing real solutions to the market. My perspective is: We are just beginning to realize our full potential as security data scientists, the best is yet to come!
To find out how in detail we are going to realize our full potential, join me in this series of further blogs, where we will be diving into:
- How does a security data science team operate?
- Business value
- Metrics
- Risk quantification
- Decision support vs. decision making with ML
- Precision vs. recall – how do we balance false positives and false negatives?
- Northstar: what does the SOC of the future look like?





